
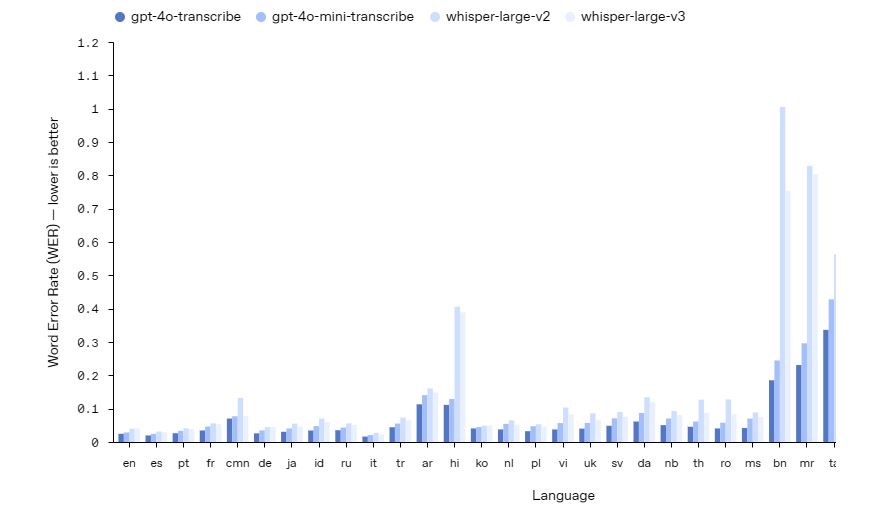
AI audio has gotten quite realistic over the years. ElevenLabs, Hume, Sesame, and others have already many ways for you to generate realistic audio for your projects. OpenAI has launched new new speech-to-text and text-to-speech audio models in the API, so you can make customizable voice agents. You can now instruct these models to speak in specific ways.
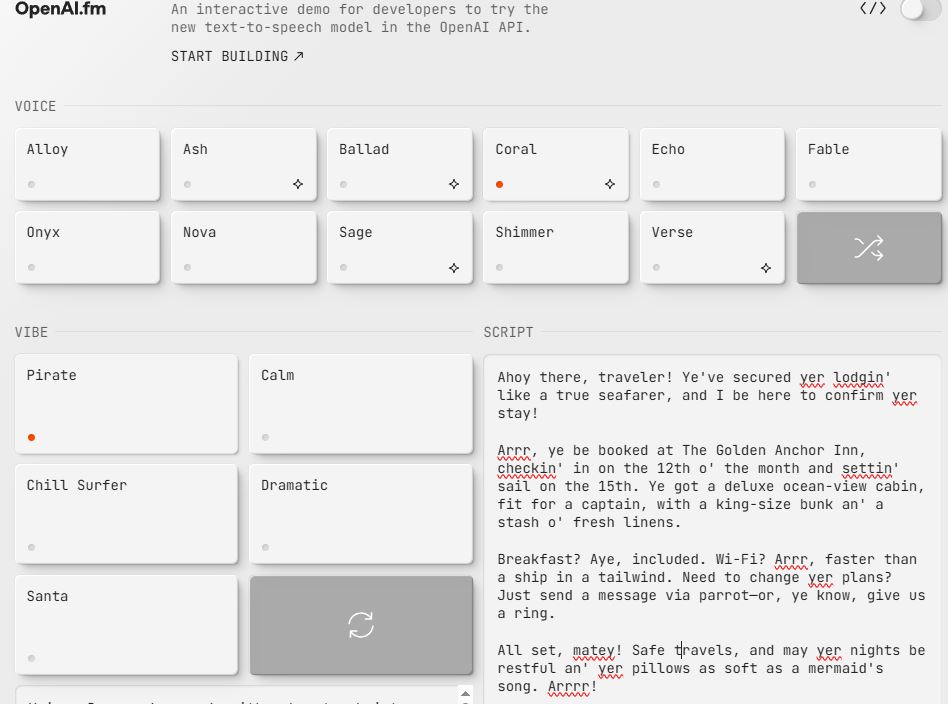
As OpenAI explain on their blog, you can make calm, professional, and various other voice styles. gpt-4o-transcribe and gpt-4o-mini-transcribe have better language recognition and accuracy. There is an interactive demo available for developers to get a better sense how these models work.
[HT]