
Many of us have used various top LLM AI tools to generate content and get answers to our questions in the past. AI models like OpenAI’s ChatGPT and Google’s Bard are well-known for their conversational abilities. However, these solutions are entirely cloud-based. Alexa and Siri can answer basic questions but are limited in many ways. They are also cloud based. Running a local AI model on a weak hardware is not ideal. They can also be time consuming to set up. As NVIDIA reports, Leo AI and Ollama can bring accelerated local LLMs to Brave browser.
This technology relies on NVIDIA GPUs and Tensor cores to handle massive amounts of calculations simultaneously. Llama.cpp is an open-source library and framework used by Leo AI to pull it off.
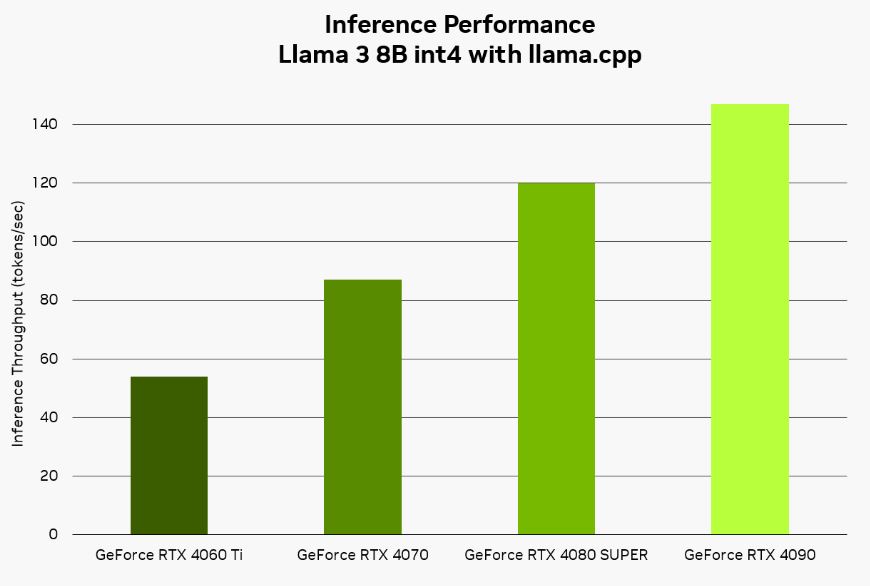
Brave’s Leo AI can run in the cloud or locally on a PC through Ollama. When you use a local model, you don’t have to worry about your privacy being compromised. With a RTX graphics card, you can run AI models fast. Using the Llama 3 8B model, you can expect up to 110 words per second. Once you download Ollama, you can run a variety of models locally from the command line.