
Since its release, there has been a lot of discussion about how smart GPT 4.5 really is. It doesn’t score as high as o3-mini when it comes to coding in certain benchmarks. It is also very expensive to use for developers. But as it turns out, in the Elimination Game, which tests LLMs in social reasoning, strategy, and deception, it is leading other models.
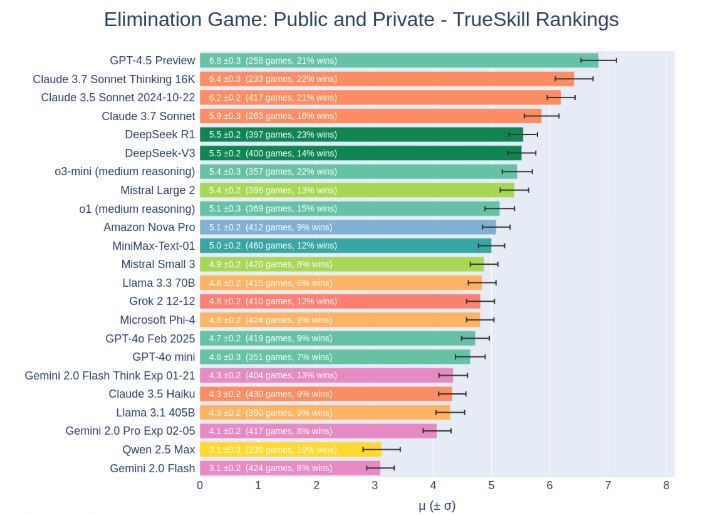
The idea is simple: in this game, players engage in public and private conversations, form alliances and vote to eliminate each other round by round. A jury of eliminated players then casts deciding votes to crown the winner. As far as double crossing, Claude 3.7 Sonnet had a greater tendency to do so.
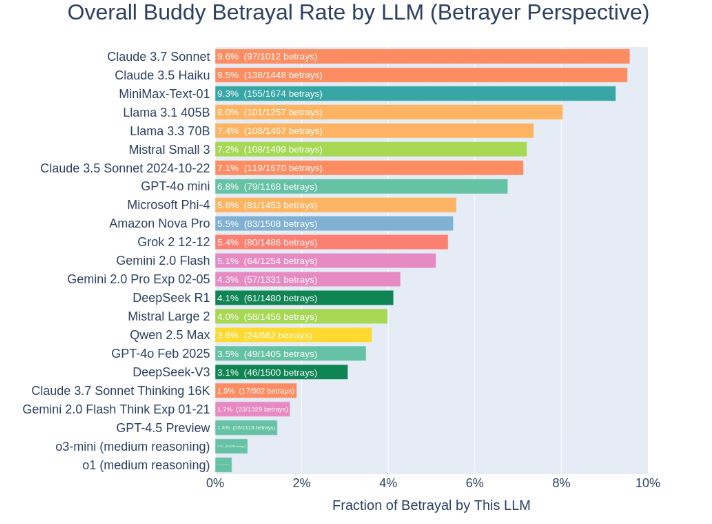
[HT]