

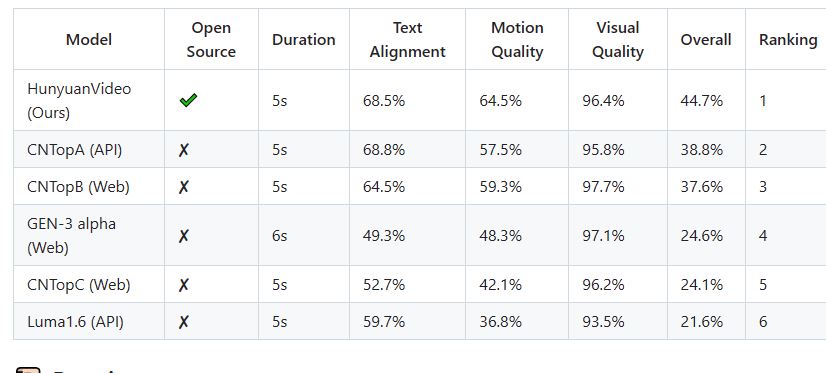
Many of us are excited about tools such as Kling, Runway, and Hailuo. Open source models have been around but they don’t offer the same quality. Tencent’s HunyuanVideo aims to change that. It is an open source video model that offers video generation performance comparable to closed-source models.
As the researchers explain:
“model learning, including data curation, image-video joint model training, and an efficient infrastructure designed to facilitate large-scale model training and inference. Additionally, through an effective strategy for scaling model architecture and dataset, [they] successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models.”
Text prompts are encoded using a large language model with Gaussian noise and condition taken as input. As the researchers explain, they use a Multimodal Large Language Model (MLLM) with a Decoder-Only structure as their text encoder. That enables this model to better image-text alignment. You can find out more on GitHub.